
The recent disclosure of GPUHammer vulnerabilities targeting NVIDIA GPU memory represents more than just another security flaw—it’s a clear signal that AI infrastructure faces fundamental security challenges that demand immediate attention. Researchers demonstrated successful bit-flips in NVIDIA A6000 GPUs, which can reduce AI model accuracy from 80% to less than 1% by strategically corrupting floating-point model weights. This dramatic impact illustrates how vulnerabilities in AI hardware can have consequences far beyond traditional data corruption.
As organizations worldwide accelerate their AI infrastructure buildout, security considerations have often taken a backseat to performance optimization and rapid deployment. The GPUHammer vulnerability serves as a wake-up call that this approach is no longer sustainable. AI infrastructure requires a fundamentally different security approach, one that acknowledges the unique risks and amplified consequences of security failures in AI systems.
AI Hardware’s Security Maturity Gap
The root of the GPUHammer problem lies in a fundamental difference between AI hardware and traditional computing infrastructure. CPUs have benefited from decades of security research, hardening, and real-world testing in enterprise environments. GPUs, by contrast, are relatively new to data center environments at scale, with security research historically focused on graphics workloads rather than enterprise computing applications.
OpenAI recognized this challenge in their March 2024 blog post about AI infrastructure security: “Trusted computing is not a new concept: these principles have long been attainable on conventional CPUs anchored on hardware trusted platform modules or trusted execution environments. However, these capabilities eluded GPUs and AI accelerators until recently, and early versions of confidential computing for GPUs are just hitting the market.”
The blog post proved prescient, noting that “confidential computing technologies on CPUs have had their share of vulnerabilities, and we cannot expect GPU equivalents to be flawless.” GPUHammer validates this concern by demonstrating how older attack techniques can be successfully adapted to newer hardware with potentially devastating consequences.
The GPUHammer attack works by exploiting RowHammer vulnerabilities in GPU memory, specifically targeting NVIDIA GPUs with GDDR6 memory. The attack overcomes GDDR6 memory protections through parallel hammering techniques and bypasses existing mitigations, such as Target Row Refresh. What makes this particularly concerning is that researchers successfully adapted an attack methodology from traditional computing to GPU hardware, suggesting that many more such adaptations may be possible.
The impact amplification in AI contexts cannot be overstated. Traditional data corruption might affect individual files or database records, but AI model weight corruption affects the core decision-making capabilities of mission-critical systems. When AI models make decisions based on corrupted weights, the effects cascade through entire business processes, and the source of degraded performance becomes nearly impossible to trace back through complex training pipelines.
Cross-Tenant Risks in AI Data Centers
The performance demands of AI workloads have led many organizations to adopt bare metal infrastructure, particularly through neo-cloud providers that specialize in AI-optimized hardware. This approach delivers measurable performance benefits but introduces unique security challenges, particularly around tenant isolation.
GPUHammer creates a new attack vector in shared GPU environments. As noted in The Hacker News coverage, “In shared GPU environments like cloud ML platforms or VDI setups, a malicious tenant could potentially launch GPUHammer attacks against adjacent workloads, affecting inference accuracy or corrupting cached model parameters without direct access. This creates a cross-tenant risk profile not typically accounted for in current GPU security postures.”
This cross-tenant risk becomes particularly problematic when combined with the hardware reclamation processes common in AI data centers. Providers typically allocate dedicated GPU servers to individual customers for optimal performance, then reclaim and redeploy the hardware to new tenants. If malicious code or corruption persists across these transitions, subsequent tenants inherit security risks from previous users.
The challenge mirrors other hardware-level vulnerabilities, such as CVE-2024-54085, a high-risk (CVSS 10.0) remotely exploitable authentication bypass affecting AMI MegaRAC BMC firmware, which is widely deployed in data centers and likely in AI infrastructure worldwide. These firmware-level vulnerabilities can persist across tenant transitions, creating persistent security risks that traditional cloud security models often fail to address adequately.
OpenAI’s infrastructure blog emphasizes the importance of robust tenant isolation: “AI workloads and assets cannot be compromised by technical or operational vulnerabilities originating from the infrastructure provider. AI systems must be resilient to cross-tenant access.” GPUHammer represents precisely the type of vulnerability that challenges current assumptions about isolation in AI infrastructure.
Multi-Layer Vulnerability Stack in AI Infrastructure
GPUHammer illustrates a broader pattern emerging in AI infrastructure security: vulnerabilities are appearing simultaneously across multiple layers of the technology stack. This creates a compound risk environment where attackers can exploit weaknesses at any layer to compromise AI workloads.
At the hardware layer, GPUHammer joins other significant vulnerabilities, such as the Cloudborne attacks discovered by Eclypsium in 2019, which exploit firmware vulnerabilities in server management systems. This allows attackers to implant malicious code in Baseboard Management Controller (BMC) firmware that persists across tenant transitions. These hardware-level attacks achieve persistence that survives OS reinstallation, hypervisor resets, and standard security measures.
Moving up the stack, recent vulnerabilities in NVIDIA’s container toolkit demonstrate that the software layer adds its own attack surface above the hardware vulnerabilities. Container escape possibilities in GPU-accelerated workloads create new attack vectors that didn’t exist in traditional CPU-only environments. Containerized AI workloads, while providing deployment flexibility, introduce additional complexity in security monitoring and isolation.
This multi-layer vulnerability pattern reflects a fundamental challenge in AI infrastructure development: security has been treated as an afterthought rather than a foundational requirement. The rapid pace of AI adoption has prioritized capability and performance over security considerations, creating a technical debt that’s now coming due.
Complex Environments and Chained Exploits
The compounding risk problem becomes clear when considering how attackers might chain exploits across layers. A hardware vulnerability, such as GPUHammer, could be combined with container escape techniques to achieve persistent access across both hardware reclamation cycles and software deployment updates. Traditional security tools, designed for conventional computing environments, often lack visibility into these AI-specific attack chains.
As AI systems become more central to business operations and decision-making, the urgency of addressing these security gaps increases dramatically. The business and operational risks associated with compromised AI systems extend far beyond traditional data breaches, potentially impacting the accuracy and reliability of critical automated decisions.
The Defensive Response and Its Trade-offs
NVIDIA’s response to GPUHammer highlights the classic tension between security and performance that pervades AI infrastructure decisions. The company recommends enabling System-level Error Correction Codes (ECC) to mitigate the vulnerability; however, this mitigation has the potential to introduce performance overhead for workloads running on affected GPUs.
This trade-off encapsulates the broader challenge that organizations face when deploying AI infrastructure. Performance optimization has been the primary driver of AI hardware adoption; however, security requirements are increasingly demanding compromises that may reduce the performance advantages that initially justified bare metal deployment.
The broader implications extend beyond individual mitigations to fundamental questions about AI infrastructure architecture. Organizations require specialized monitoring capabilities for AI hardware, hardware attestation systems tailored to GPU environments, and security frameworks designed around AI-specific threat models, rather than adapting traditional enterprise security approaches.
Market dynamics add another layer of complexity to these decisions. ABI Research forecasts that neocloud providers will generate over $65 billion in GPU-as-a-Service revenues by 2030, indicating sustained market demand for specialized AI infrastructure despite growing security concerns. Organizations must balance performance needs with security risks in an environment where demand consistently exceeds projections.
The security industry must also adapt to support these emerging requirements. Traditional security tools often lack visibility into GPU memory operations, firmware-level monitoring capabilities, and the ability to detect AI-specific attacks. The rapid evolution of AI hardware compounds this challenge, as security solutions must keep pace with constantly changing hardware architectures and deployment models.
Preparing for the Next Wave
GPUHammer should be viewed as the first of many CPU-to-GPU vulnerability adaptations rather than an isolated incident. The pattern suggests that attackers will systematically adapt existing attack techniques to AI hardware, potentially discovering new vulnerabilities that exploit the unique characteristics of GPU architectures and AI workloads.
This pattern recognition creates an opportunity for proactive security investment. Organizations that acknowledge the security maturity gap in AI hardware can begin building appropriate defenses before facing active exploitation. This includes investing in GPU-specific security tooling, developing incident response procedures adapted to AI infrastructure, and implementing continuous monitoring capabilities that provide visibility into hardware-level threats.
Strategic recommendations for organizations include implementing comprehensive risk assessment frameworks that consider the multi-layer vulnerability stack in AI infrastructure. Hybrid deployment strategies often provide optimal balance, utilizing bare metal infrastructure for performance-critical production workloads while maintaining virtualized environments for development, testing, and variable workloads where security requirements may outweigh performance considerations.
The most critical requirement is developing organizational expertise that understands the unique security challenges of AI infrastructure. This includes technical knowledge of GPU security architectures, awareness of AI-specific threat models, and operational experience with hardware attestation and firmware monitoring systems.
Security Can No Longer Be an Afterthought
The GPUHammer vulnerability marks a significant milestone in AI infrastructure security. The combination of hardware-level attack persistence, cross-tenant risk vectors, and multi-layer vulnerability stacks creates a threat environment that traditional security approaches cannot adequately address.
Organizations deploying AI infrastructure must recognize that security considerations cannot be deferred until after performance optimization and rapid deployment goals are met. The business risks of compromised AI systems—from degraded model accuracy to corrupted training data—are too significant to address reactively.
Success in AI infrastructure security requires matching deployment strategies to specific workload requirements while maintaining comprehensive security practices throughout the infrastructure lifecycle. This includes implementing hardware attestation capabilities, continuous firmware monitoring, and specialized incident response procedures designed for the unique characteristics of AI infrastructure.
The path forward demands investment in both technology and expertise. Organizations must develop internal capabilities that understand AI-specific security risks while working with providers who demonstrate mature security practices and transparent security implementations. The $65 billion market for GPU-as-a-Service represents enormous opportunity, but only for those who can successfully balance performance requirements with comprehensive security practices.
As the AI infrastructure landscape continues to evolve at an unprecedented speed, security must become a foundational requirement rather than an operational afterthought. The GPUHammer vulnerability provides a clear preview of the challenges ahead—and an opportunity to build defenses before facing the next wave of AI-targeted attacks.
How Eclypsium Can Help
Eclypsium provides hardware and firmware-level vulnerability monitoring, threat detection, and compensating controls for AI data centers. Eclypsium can discover vulnerable devices and components in your environment, including devices with DRAM vulnerable to the GPUHammer attacks, and BMCs vulnerable to CVE-2024-54085. To learn more please visit our AI Data Center solution page.
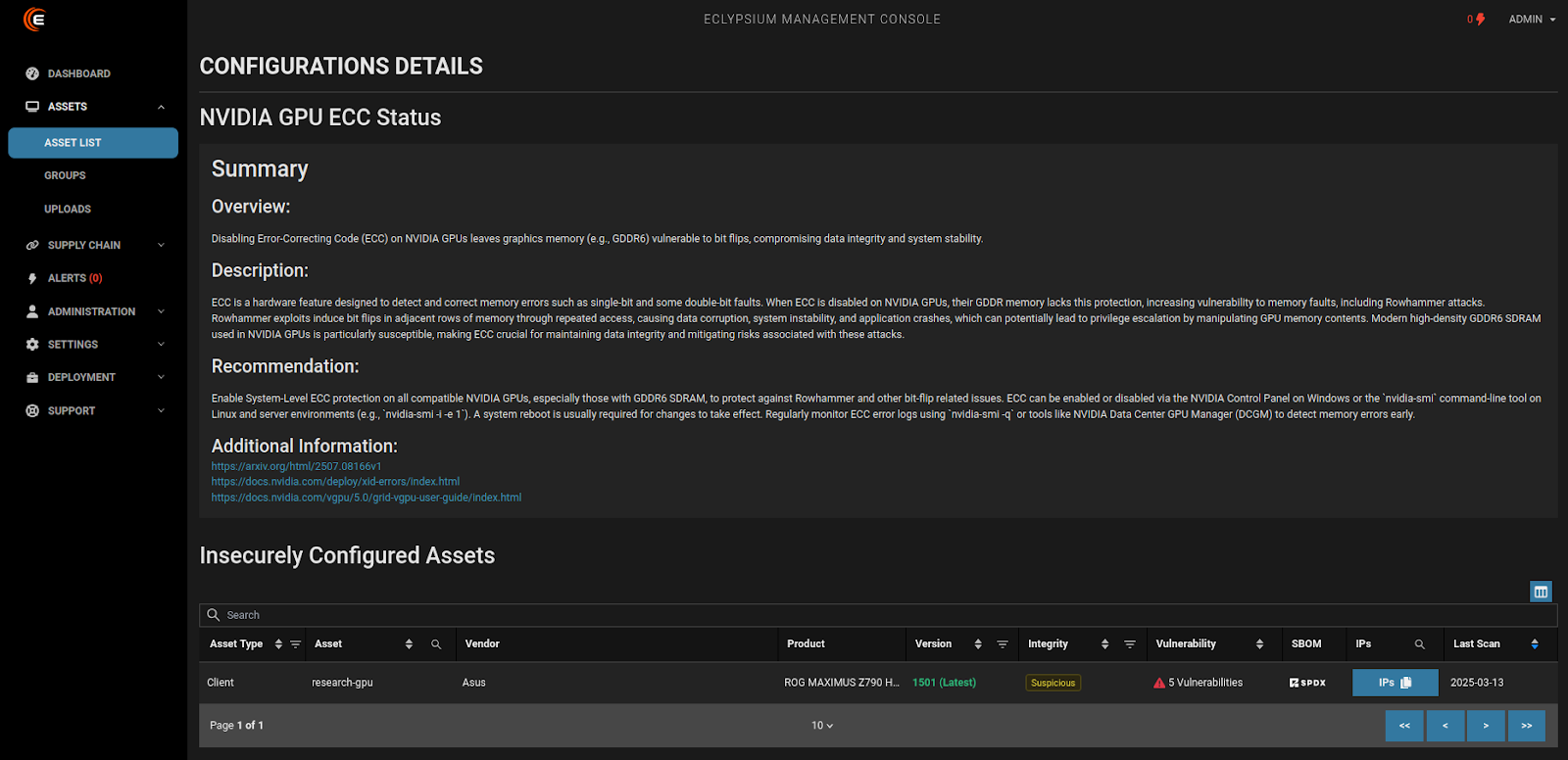
On top of that, Eclypsium is able to identify whether Error Correction Codes (ECC) are enabled to mitigate against GPUHammer attacks. This helps you map your attack surface for this vulnerability and assure you have the appropriate mitigations in place across your GPU fleet.
Get The Ultimate Guide to AI Data Center Cybersecurity
Eclypsium can monitor AI infrastructure, from GPU servers to BMCs to network equipment throughout the environment, to reduce the attack surface of AI infrastructure before, during, and after deployment.
Get our Ultimate Guide to AI Data Center Security for a clear plan to assess the security of neocloud providers, or of your own AI hardware deployment plans, and to protect your assets in production against nation-state threats, ransomware gangs, and zero days.



